How stagewise Reads Files Without Depending on the Model API
TechnicalWe're taking a closer look at the file transformation pipeline in stagewise, and how it turns files into model-agnostic inputs instead of relying on provider-specific parsing.
Why file access matters
Agents work on files constantly. They read them for context, change them, and then check the result after a change. In coding and other knowledge work, that is not a side task. It is a big part of the job.
That makes file reading one of the core efficiency problems in an agent. If reading files is slow, limited, or inconsistent, the rest of the workflow gets worse with it.
The usual approach breaks down quickly
The standard way to handle files with LLMs is to rely on the model provider's API. You upload a file, the provider parses it, and the model sees whatever the API decides to expose.
That works for a narrow set of file types: usually PDFs, common image formats, and sometimes a few office document formats. The problem is that the supported set is small, different providers expose different capabilities, and support can change depending on the model or platform you use. The same model can behave differently depending on whether it is running through a direct API, Google Vertex, Amazon Bedrock, or something else.
There is also a hard ceiling on what this approach can do. Bigger files become difficult or impossible to expose cleanly. Existing agents often work around that by using CLI tools to parse files in a shell-like way, but that mainly helps with text and metadata. Visual content still needs a separate path. Self-hosted models and custom inference stacks fall even further behind, which makes the whole system less portable.

The core idea: reduce files to basic modalities
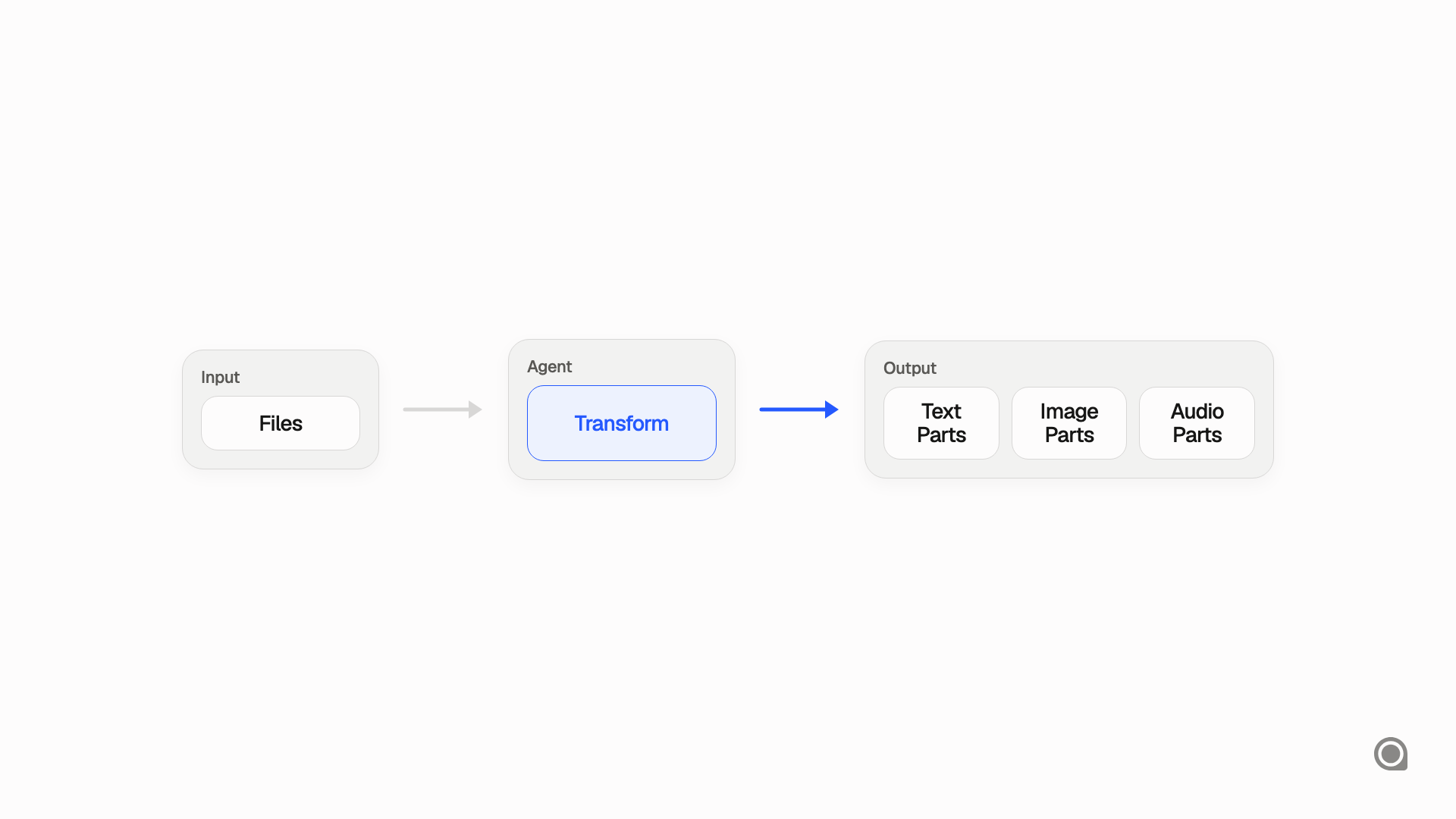
The useful shift was to stop treating files as special API objects and start treating them as message content.
Instead of assuming a message part has to be "a file," stagewise breaks it down into simpler chunks of information with clear modalities: text, image, or audio where relevant. Once you do that, many more files become readable across many more models.
That is the basis of the file transformation pipeline inside the stagewise agent. Its job is to take a file and turn it into a structured set of content parts that models can consume without depending on provider-specific file parsing.
What the pipeline produces
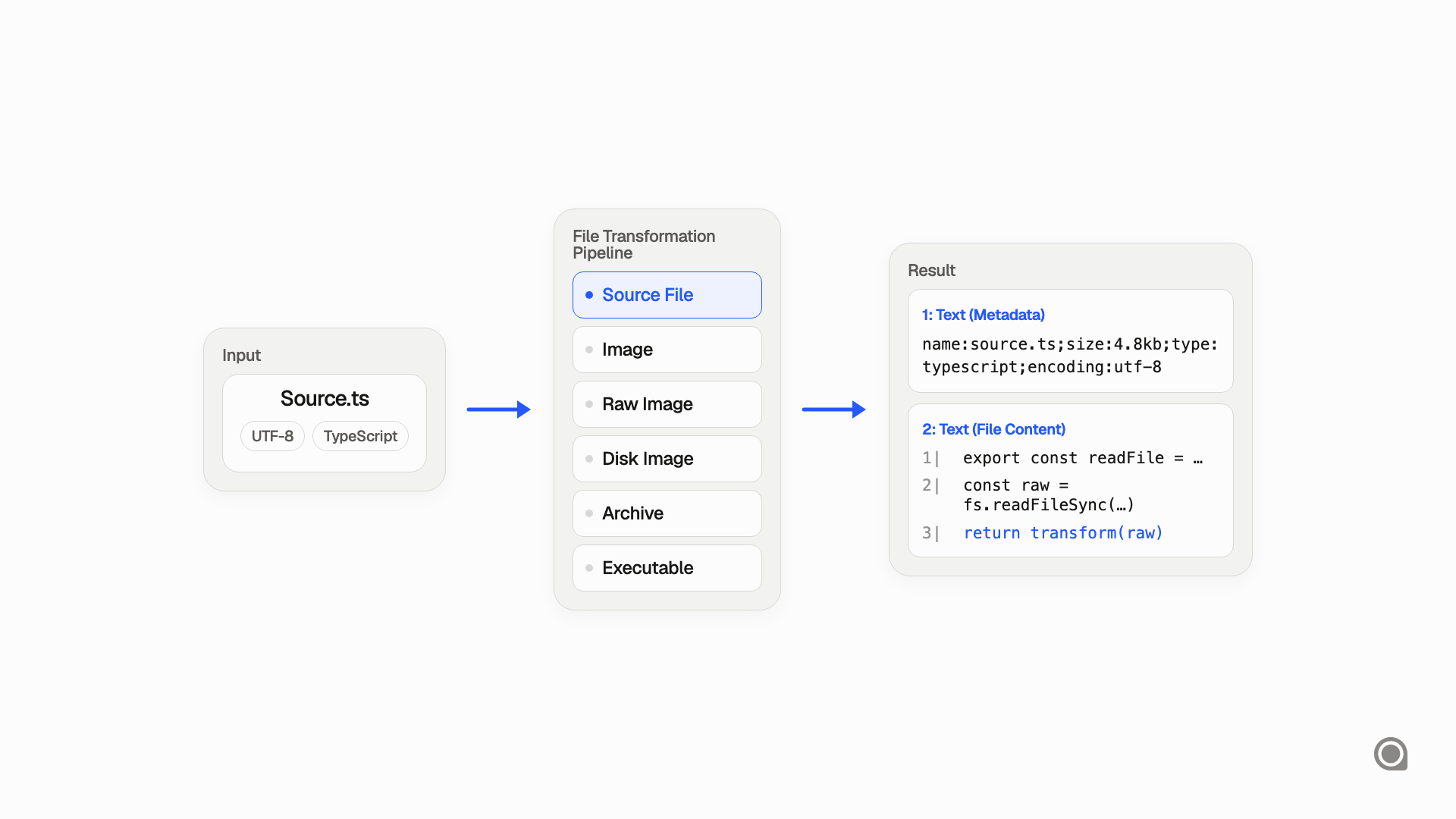
Source files
A source file can become text with file metadata, line-number prefixes, and room for richer structure later. Those line prefixes do more than help navigation. They also give the model a clearer frame for how to interpret the content.
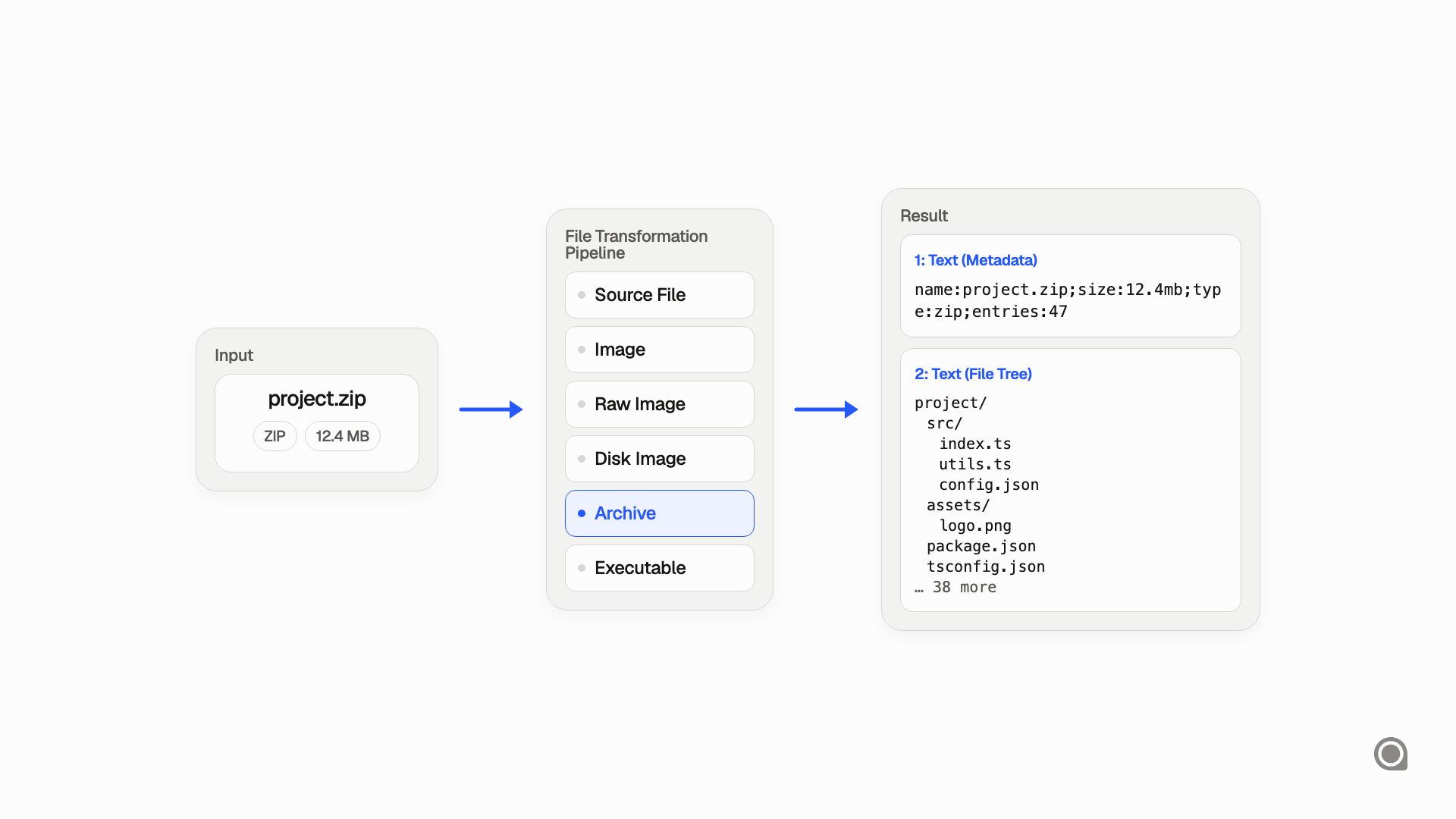
Archives
Archives and disk images can be transformed into metadata and a preview of the contained file tree. The tree is compact and does not need line numbers — it is structural information, not source code.
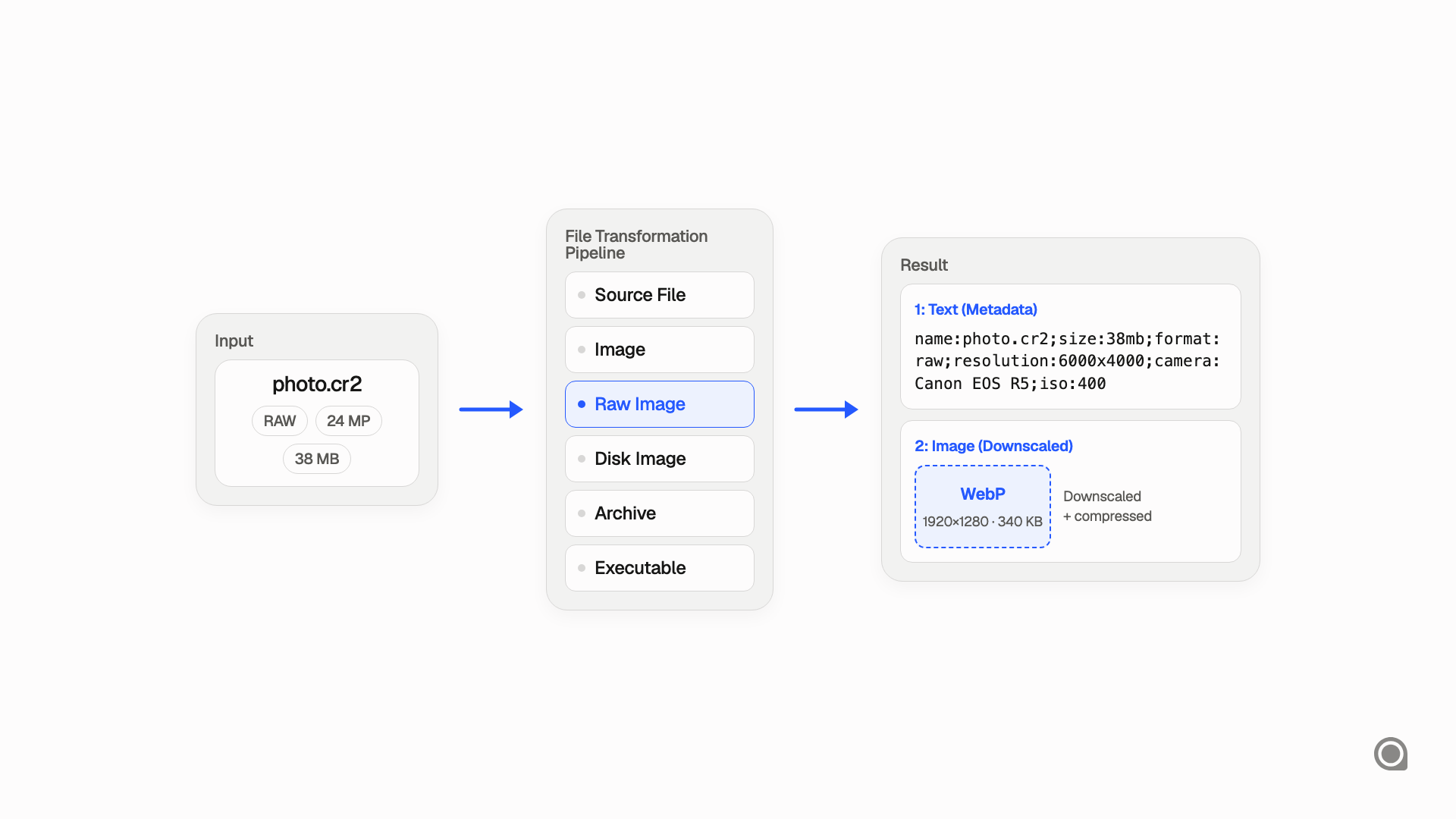
Images
An image file can become a text part with metadata and source-format details, plus an efficiently encoded visual representation that fits within model limits. Large or raw images are downscaled and compressed to WebP before being sent to the model.
The important point is not the exact representation of each file type. It is that every file ends up as a list of textual, visual, or auditory parts that are independent of any single model API.
Why this matters
This makes multimodal file reading far less dependent on the provider underneath the model. Frontier models benefit from that, but smaller models and self-hosted setups benefit even more because they are usually the first ones to lose access to advanced provider-side parsing.
It also helps with efficiency. Once files are transformed into a standard representation, the agent can handle pagination, line limits, and similar controls in a more consistent way across file types. Models do not need a different reading strategy for every format.
The pipeline is also meant to be extended. New file types can be supported by adding new transformers, and existing ones can keep improving as we learn more. The current transformer implementations live here:
Still early, but already useful
This work is still in an early research phase, and the pipeline is likely to change. That said, the results are already promising enough that we shipped it in stagewise 1.0.0-alpha.46.
We also welcome contributions that expand support for more file types or improve the transformations that already exist.